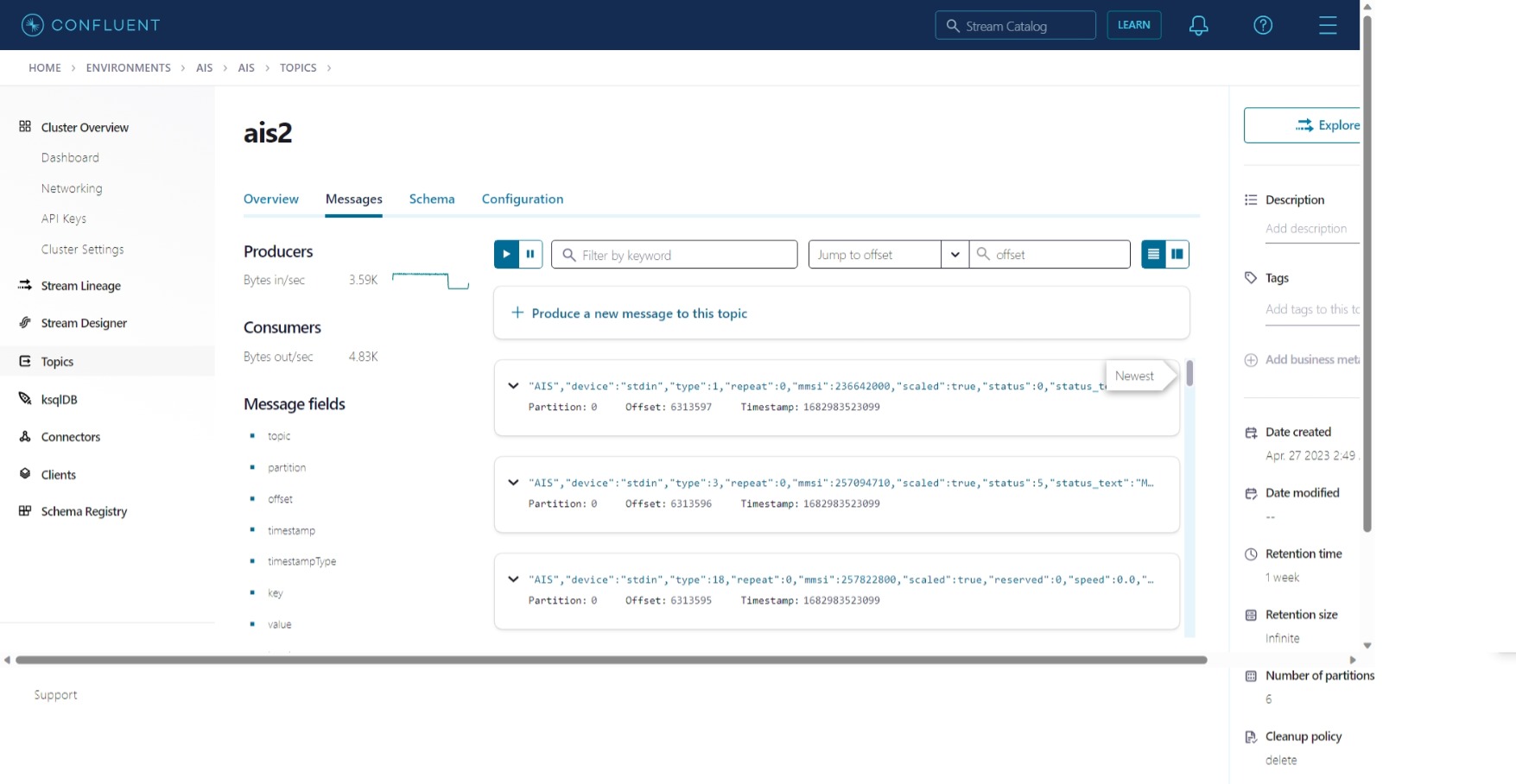
kafkacat and AIS messages
kcat
git clone https://github.com/edenhill/kcat.git
cd kcat
bash bootstrap.sh
./configure
make
sudo make install
Apache Kafka® 101
Lesson 1. Events | Confluent Developer
Kafka is based on the abstraction of a distributed commit log. By splitting a log into partitions, Kafka is able to scale-out systems. As such, Kafka models events as key/value pairs. Internally, keys and values are just sequences of bytes, but externally in your programming language of choice, they are often structured objects represented in your language’s type system. Kafka famously calls the translation between language types and internal bytes serialization and deserialization. The serialized format is usually JSON, JSON Schema, Avro, or Protobuf.
Values are typically the serialized representation of an application domain object or some form of raw message input, like the output of a sensor.
Lesson 3. Topics | Confluent Developer
Events have a tendency to proliferate—just think of the events that happened to you this morning—so we’ll need a system for organizing them. Apache Kafka’s most fundamental unit of organization is the topic, which is something like a table in a relational database. As a developer using Kafka, the topic is the abstraction you probably think the most about. You create different topics to hold different kinds of events and different topics to hold filtered and transformed versions of the same kind of event.
A topic is a log of events. Logs are easy to understand, because they are simple data structures with well-known semantics. First, they are append only: When you write a new message into a log, it always goes on the end. Second, they can only be read by seeking an arbitrary offset in the log, then by scanning sequential log entries. Third, events in the log are immutable—once something has happened, it is exceedingly difficult to make it un-happen. The simple semantics of a log make it feasible for Kafka to deliver high levels of sustained throughput in and out of topics, and also make it easier to reason about the replication of topics, which we’ll cover more later.
Lesson 6. Brokers | Confluent Developer
Lesson 8. Producers | Confluent Developer
The API surface of the producer library is fairly lightweight: In Java, there is a class called
KafkaProducerthat you use to connect to the cluster. You give this class a map of configuration parameters, including the address of some brokers in the cluster, any appropriate security configuration, and other settings that determine the network behavior of the producer. There is another class calledProducerRecordthat you use to hold the key-value pair you want to send to the cluster.
confluentinc/demo-scene/maritime-ais
confluentinc/demo-scene/maritime-ais
We follow the above example.
We run nc locally and use kcat to send messages to the Confluent Cloud environment
env-qr9drm, to the cluster lkc-nw8d2z, to the topic ais2,
where the cluster’s bootstrap server endpoint is pkc-419q3.us-east4.gcp.confluent.cloud:9092, and
where 3FPYLWJU5MMU2TL2 is an API key for the cluster.
The syntax we end up with does not invoke the environment ID or the cluster ID, but we do not know that beforehand; above we laid out all the parameters at our disposal.
We use gpsdecode from gpsd-clients.
ENVIRONMENT_ID='env-qr9drm'
CLUSTER_ID='lkc-nw8d2z'
BOOTSTRAP_SERVER='pkc-419q3.us-east4.gcp.confluent.cloud:9092'
API_KEY='3FPYLWJU5MMU2TL2'
API_SECRET= #
nc 153.44.253.27 5631 | \
gpsdecode | \
kcat -b $BOOTSTRAP_SERVER \
-X security.protocol=SASL_SSL \
-X sasl.mechanisms=PLAIN \
-X sasl.username=$API_KEY \
-X sasl.password=$API_SECRET \
-t ais2 \
-K ':' \
-D '\n' \
-P
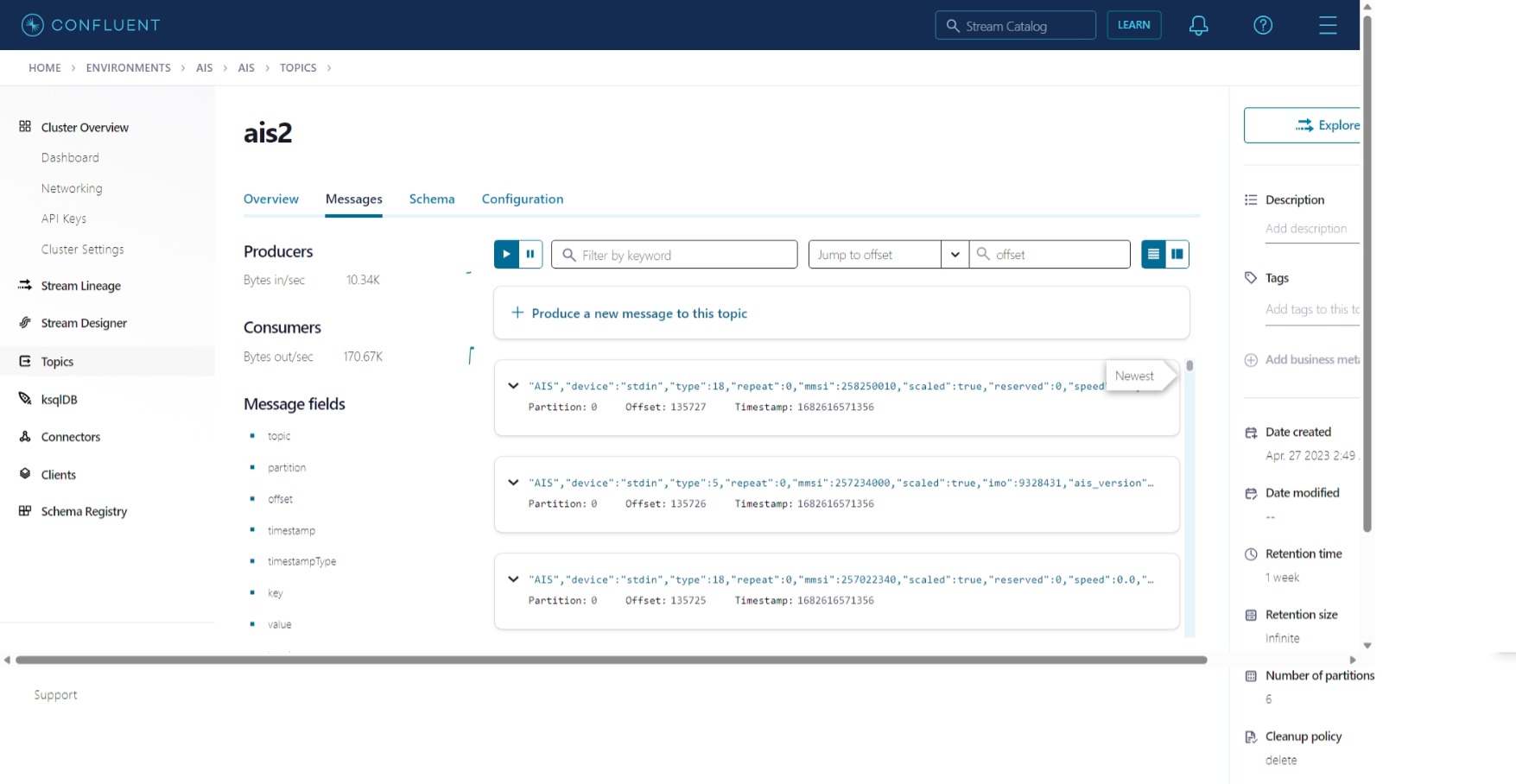
Deploying on EC2 instance
We create an EC2 instance running Ubuntu:
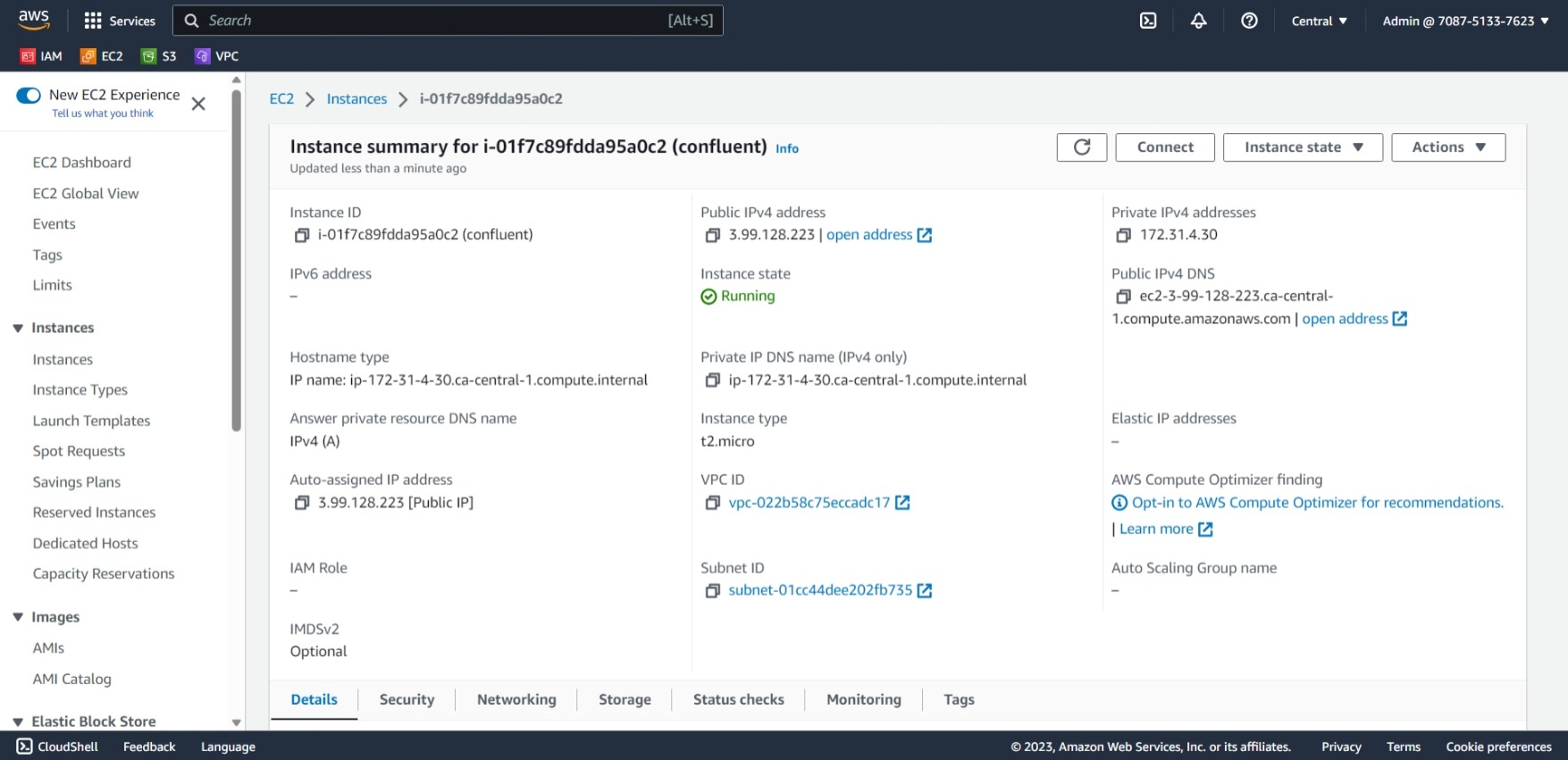
Connect to EC2 instance using OpenSSH. On WSL2, to get the permissions on the .pem file to 400,
we move it to the Ubuntu home directory: there seemed to be issues with permissions keeping it in a Windows created directory.
Connected with OpenSSH to the instance, we do the following.
Install the Confluent CLI | Confluent Documentation
cd ~/
curl -sL --http1.1 https://cnfl.io/cli | sh -s -- latest
export PATH="/home/$USER/bin:$PATH"
ENVIRONMENT_ID='env-qr9drm'
CLUSTER_ID='lkc-nw8d2z'
TOPIC_ID='ais2'
API_KEY='3FPYLWJU5MMU2TL2'
API_SECRET= #
confluent login --save
confluent environment use $ENVIRONMENT_ID
confluent kafka cluster use $CLUSTER_ID
confluent api-key store $API_KEY $API_SECRET --resource $TOPIC_ID
Then we make the file my_command.sh:
BOOTSTRAP_SERVER='pkc-419q3.us-east4.gcp.confluent.cloud:9092'
API_KEY='3FPYLWJU5MMU2TL2'
API_SECRET= #
cat > my_command.sh <<EOF
#!/bin/bash
# my_command.sh
nc 153.44.253.27 5631 | \
gpsdecode | \
kafkacat -b $BOOTSTRAP_SERVER \
-X security.protocol=SASL_SSL \
-X sasl.mechanisms=PLAIN \
-X sasl.username=$API_KEY \
-X sasl.password=$API_SECRET \
-t ais2 \
-K ':' \
-D '\n' \
-P
EOF
Kernighan and Pike, The Unix Programming Environment, Section 3.7:
The shell jargon for this construction is a here document; it means that the input is right here instead of in a file somewhere. The
<<signals the construction; the word that follows (Endin our example) is used to delimit the input, which is taken to be everything up to an occurrence of that word on a line by itself.
Then:
nohup bash my_command.sh &
exit
I did this locally rather than using EC2 Instance Connect merely to try various ways of connecting to the instance.
In Confluent Cloud, we see after exiting OpenSSH, the EC2 instance continues to send messages to the topic.
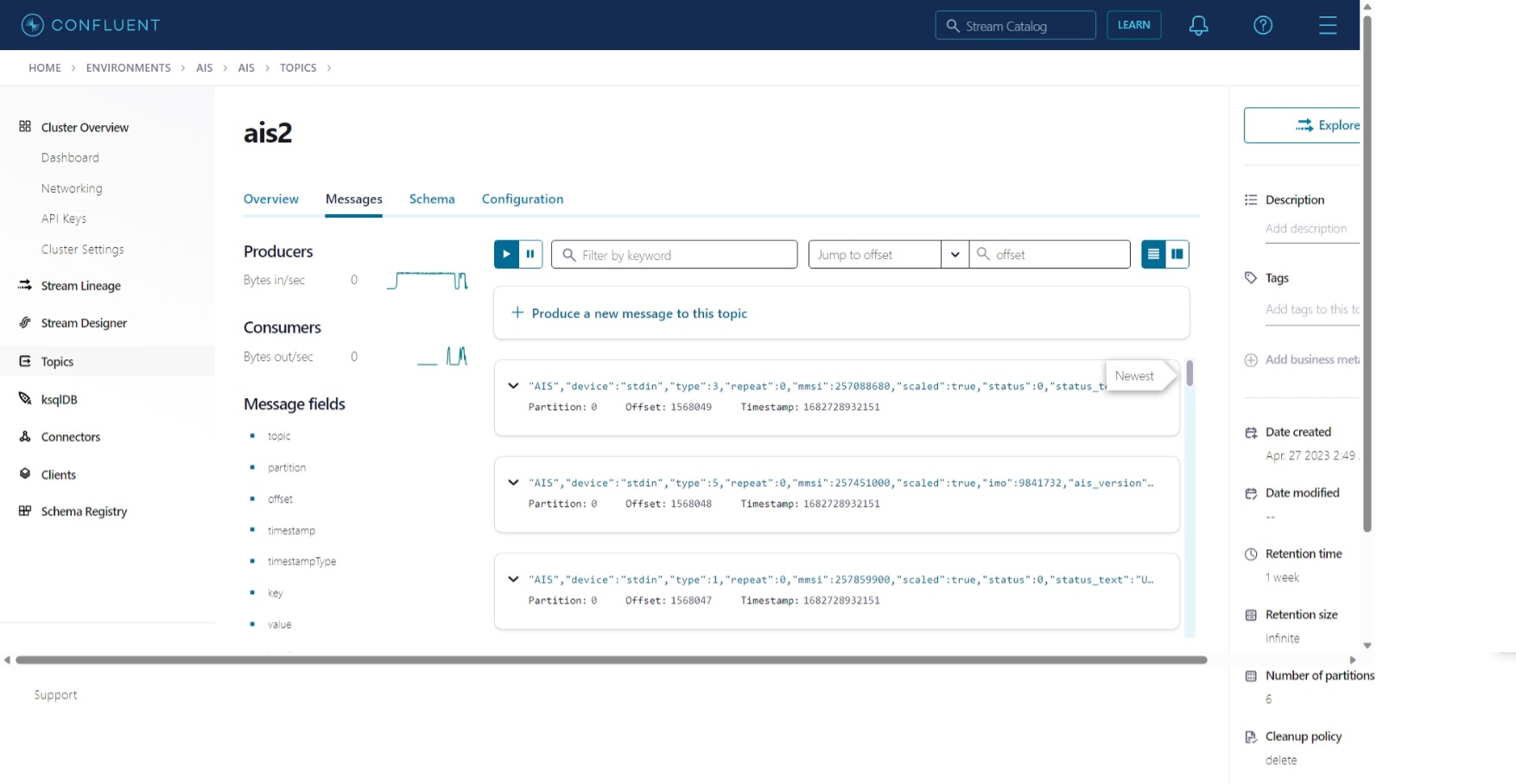
Days later (Sun Apr 30 06:05:37 UTC 2023), we connect to the EC2 instance using EC2 Instance Connect. We run
ps aux | grep kafkacat, set PID= # process ID, and kill -s SIGKILL $PID.
Next, we do the same thing on a Google Compute Engine instance.
ENVIRONMENT_ID='env-qr9drm'
CLUSTER_ID='lkc-nw8d2z'
BOOTSTRAP_SERVER='pkc-419q3.us-east4.gcp.confluent.cloud:9092'
API_KEY='3FPYLWJU5MMU2TL2'
API_SECRET= #
curl -sL --http1.1 https://cnfl.io/cli | sh -s -- latest
confluent login --save
confluent environment use $ENVIRONMENT_ID
confluent kafka cluster use $CLUSTER_ID
confluent api-key store $API_KEY $API_SECRET --resource $TOPIC_ID
sudo apt install netcat
sudo apt install kafkacat
sudo apt install gpsd-clients
cat > my_command.sh <<EOF
#!/bin/bash
# my_command.sh
nc 153.44.253.27 5631 | \
gpsdecode | \
kafkacat -b $BOOTSTRAP_SERVER \
-X security.protocol=SASL_SSL \
-X sasl.mechanisms=PLAIN \
-X sasl.username=$API_KEY \
-X sasl.password=$API_SECRET \
-t ais2 \
-K ':' \
-D '\n' \
-P
EOF
nohup bash my_command.sh &